前回はHyper-V上に作成したUbuntu上にcaffeをインストールしました。今回は実際に使ってみます。
概要
caffeは大まかに下記の手順で実施します。
- データセットの用意
- データの格納
- パラメータの調整
- 学習
- 評価
今回は、学習が完了した状態で、評価を行います。
ちなみに、データセットとは、学習(訓練)用、評価用の2種から構成されるデータ群です。
通常、学習する際に使用したデータを、検証用に使うことはできません。
学生のテストで試験範囲発表で問題そのものが公開されるわけではないのと同じです。学生を「テスト」する意味がないですから。
また、今回のテストはあらかじめ用意されているものを使います。
ネット上で解説されているものと同じですが、他と違うのは、きちんと説明を加えます。
何をしているのかよくわからないし、「おまじない」的な説明は極力避けます。
準備
モデルの取得
モデルとは、どういう手順、経路、方法でデータの学習を行うかを定義した多層ニューラルネットワークを指す。
モデルは、Caffe Model ZooというCaffeの学習済モデルを公開したWikiがあり、そこで有力なモデルが公開されている。
下記のコマンドを実行します。caffeのフォルダは前回と同様であるものとします。
必要に応じてsudoするなりします。
1 | cd /usr/local/caffe/ |
実行したスクリプトは大量のデータ (233MB) をダウンロードしますので時間がかかります。
関連データの取得
ilsvrc12の学習、評価に用いられる画像ファイル名の一覧、ラベル一覧などをダウンロードします。
1 | cd /usr/local/caffe/data/ilsvrc12/ |
画像データの取得
検証に用いる画像のデータセットCaltech 101をダウンロードします。
ダウンロード先は任意です。
126MBあるので、これも時間がかかります。
1 | cd /usr/local/caffe/ |
これで準備完了です。
検証
分類
実際に画像を入力して分類してみます。
前提として、pycaffeをコンパイル済みであるものとします。
1 | cd /usr/local/caffe/python |
classify.py によれば、
1 | #!/usr/bin/env python |
とあります。
入力と出力は必須なので、最後の2つが入力画像と出力になります。
出力はnumpy標準のファイル形式です。
--raw_scale 255 は、前処理の前にこのスケール値だけ乗算するとあります。
OpenCV 備忘録 によれば、入力値[0:1]をImageNetモデルの[0:255]に変更するとのこと。
実行後、うまくいって結果を確認、できません。
無慈悲なエラーが出ます。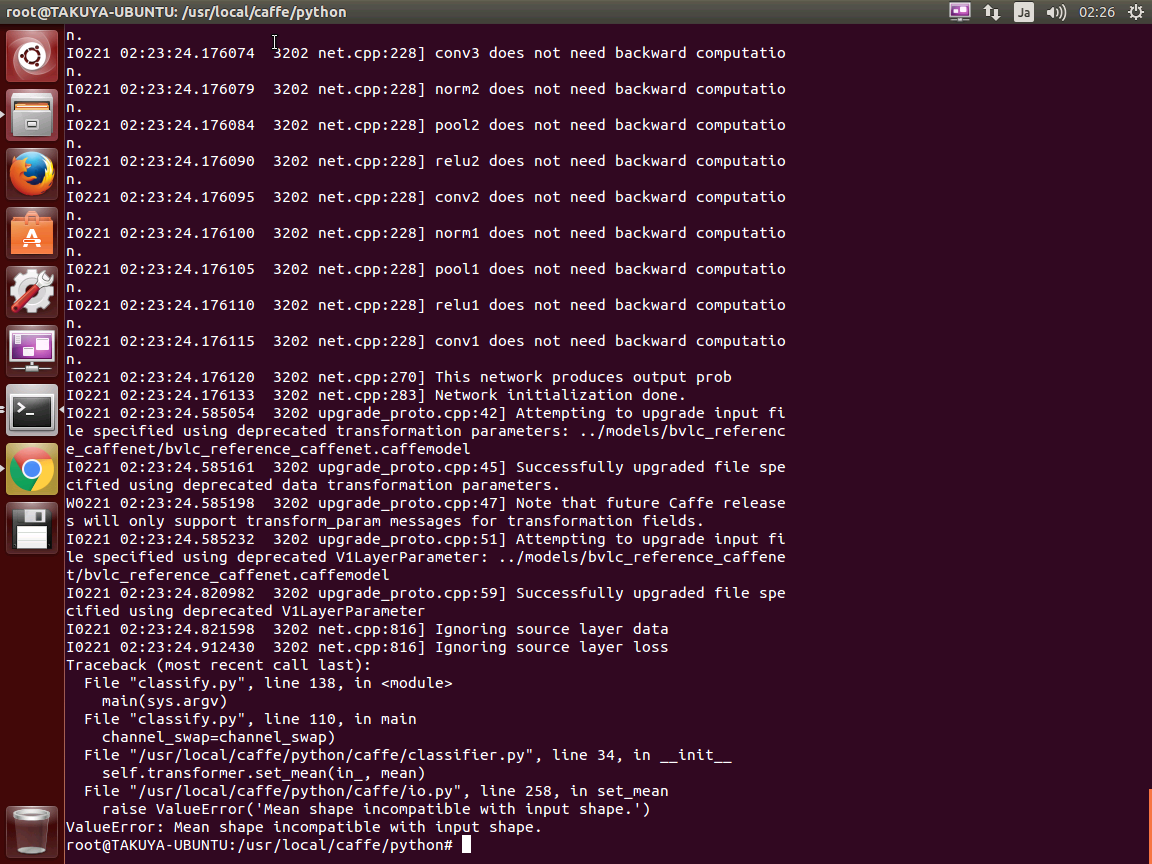
1 | File "classify.py", line 138, in |
イラっとしますが、解析すると、**/usr/local/caffe/python/caffe/io.py** の258行目が例外を投げているように見えます。
Google先生に聞いてみるとOSX10.10でCaffeをインストール、リファレンスモデルで画像を分類にて回答が。
1 | if ms != self.inputs[in_][1:]: |
を
1 | if ms != self.inputs[in_][1:]: |
に直せばよいとのこと。
修正後、再度実行すると、result.npyが出力されたことを示すメッセージが。
結果
うきうきしながら、result.npyを開くと。
開けません。というかバイナリファイルなのか読めません。
これを人間の目でわかる結果に直す必要があります。
Caffeで手軽に画像分類にて、この結果を人間の目でわかる結果に直すスクリプトを公開してくださっています。感謝です。
1 | cd /usr/local/caffe/python |
エディタを開いて下記のスクリプトを保存します。
1 | #! /usr/bin/env python |
保存後。、
1 | cd /usr/local/caffe/python |
という結果が出力されます。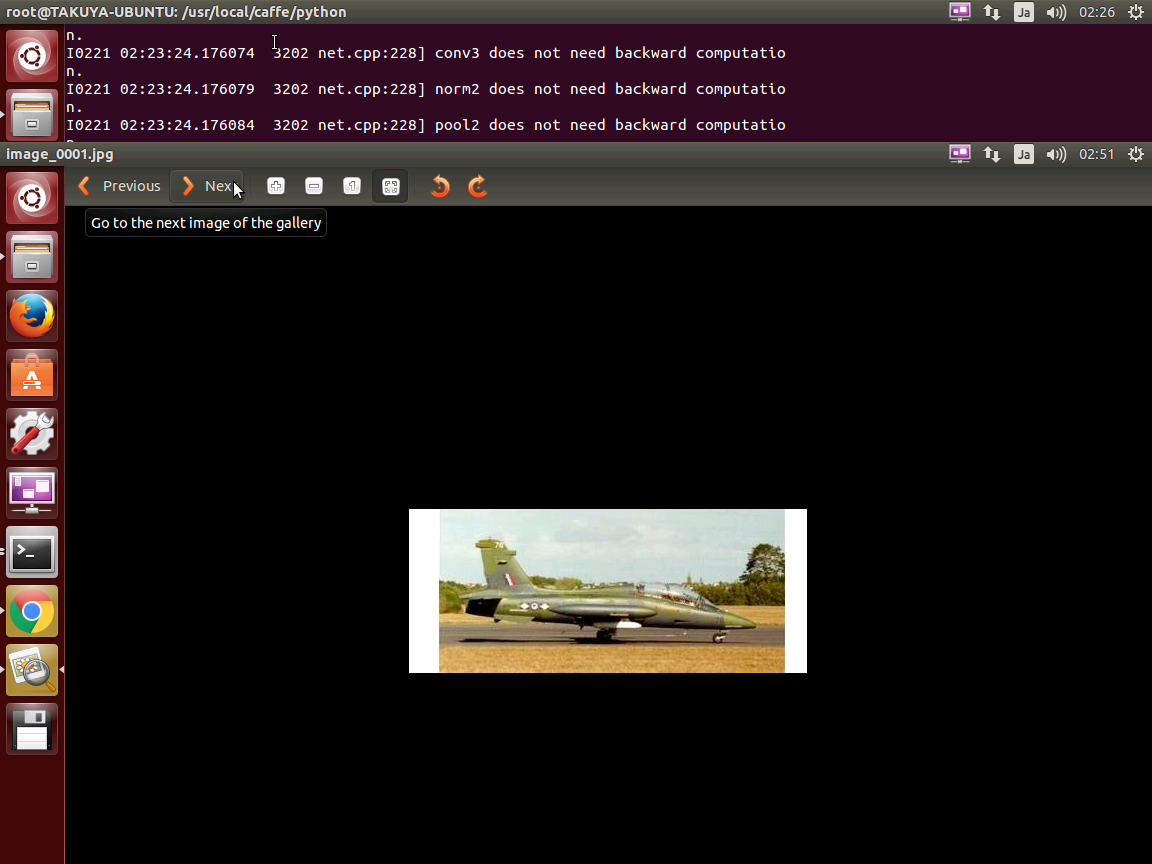
入力画像 /usr/local/caffe/dataset/caltech101/101_ObjectCategories/airplanes/image_0001.jpg が戦闘機である確率が84.8%だと判断されました。
素晴らしい。
Conclusion
長かったですが、きちんとcaffeが動作する様を確認できました。
次回はモデルを構築できたらな、と思います。