Introduction
掲題の通り。
インラインのコード補完には使えないが、チャットペインからのコード生成には十分活用できる。
How to do?
環境は下記
- モデル
- google/gemma-4-26B-A4B-it を使用する。
- vLLM
- 0.23.0
- HW
- HP ZGX Nano G1n AI Station
vLLM の起動パラメータ変更
vLLM の起動パラメータに
--tool-call-parser--enable-auto-tool-choice
を追加する。
この両方がないと Visual Studio Code 側で
1 | sorry, your request failed. Please try again. Client Request Id: df0180b9-6e7b-4186-8c40-dc27fd2bbe9e Reason: Request Failed: 400 {"error":{"message":""auto" tool choice requires --enable-auto-tool-choice and --tool-call-parser to be set","type":"BadRequestError","param":null,"code":400}}: Error: Request Failed: 400 {"error":{"message":""auto" tool choice requires --enable-auto-tool-choice and --tool-call-parser to be set","type":"BadRequestError","param":null,"code":400}} at LG._provideLanguageModelResponse (/home/t-takeuchi/.vscode-server/cli/servers/Stable-7e7950df89d055b5a378379db9ee14290772148a/server/extensions/copilot/dist/extension.js:1690:14355) at process.processTicksAndRejections (node:internal/process/task_queues:104:5) at async LG.provideLanguageModelResponse (/home/t-takeuchi/.vscode-server/cli/servers/Stable-7e7950df89d055b5a378379db9ee14290772148a/server/extensions/copilot/dist/extension.js:1690:15320) |
のようなエラーが出てしまう。--tool-call-parser はモデルによって指定する値が異なる。
Gemma を使うので Gemma 4 Usage Guide を参考にした。
最終的に下記のようなパラメータで起動した。
1 | export model="google/gemma-4-26B-A4B-it" |
Visual Studio Code 側の設定
正直、今の VSCode の UI の設定はわかりづらい。
コマンドパレットから移動すれば一発なんだけど。
コマンドパレットから Chat: Manage Language Models を選択…と言いたいが、この先の Language Model ダイアログからの設定はわかりづらいし、設定にエラーが出るとバグなのかほかの選択肢が出なくなるので手動で入力する。
%USERPROFILE%\AppData\Roaming\Code\User\chatLanguageModels.json をエディタで開く。
1 | [ |
カスタイマイズ箇所は
- name
- モデルのカテゴリ。自由に設定できる
- models.id
- モデルの名前。vLLM に渡す起動パラメータ
--modelと合わせる
- モデルの名前。vLLM に渡す起動パラメータ
- models.name
- モデルの表示名。VSCode 上に表示される名前
- models.url
- vLLM の待ち受けエンドポイント。
maxInputTokens や maxOutputTokens は自由に。toolCalling は true にすること。v1/chat/completions まで含めること。
ファイルを保存後、コマンドパレットから Chat: Manage Language Models に移動すると下記のようになっていることを確認。
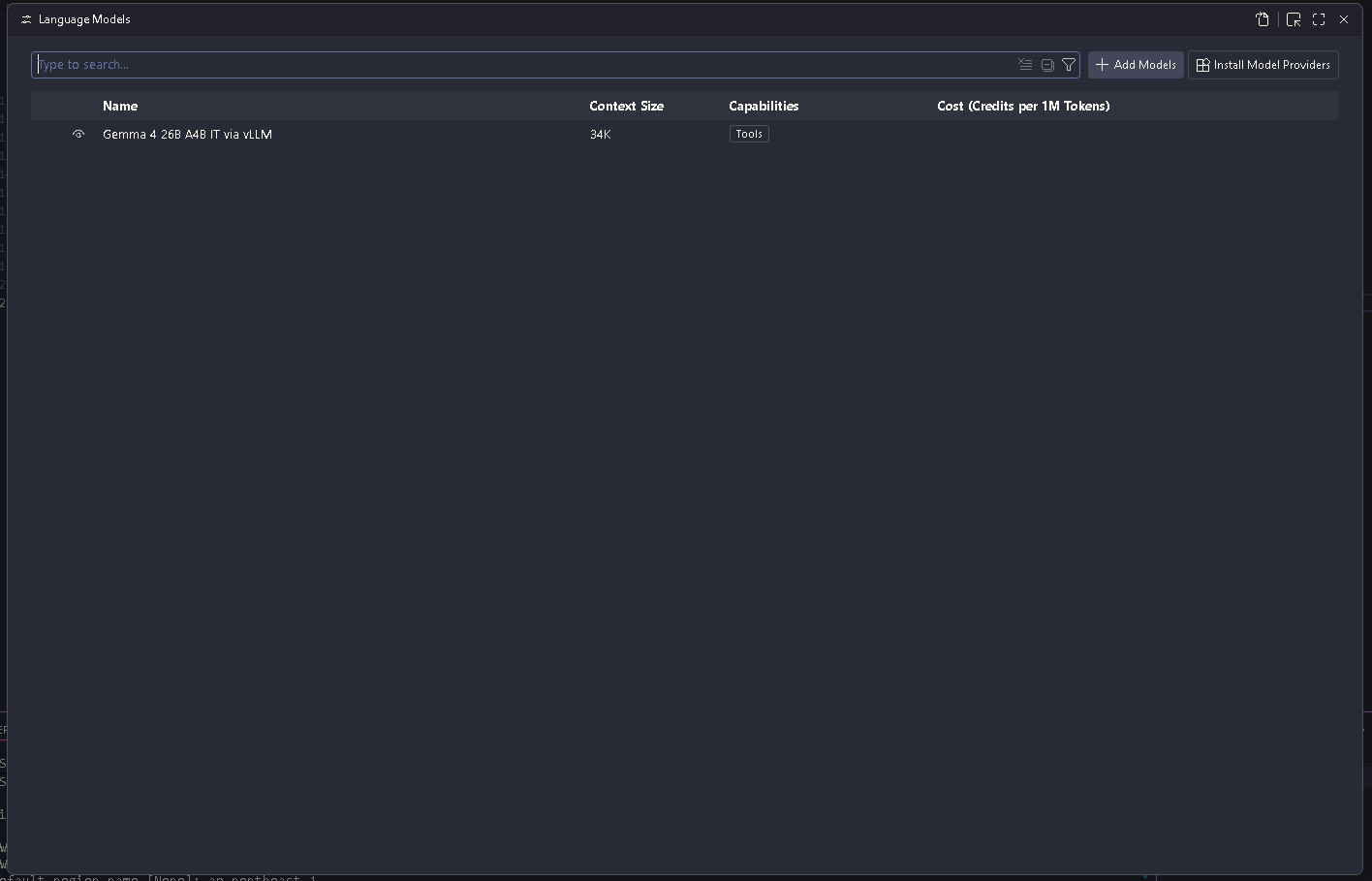
あとはチャットペインでモデルを選択しプロンプトを投げるだけ。
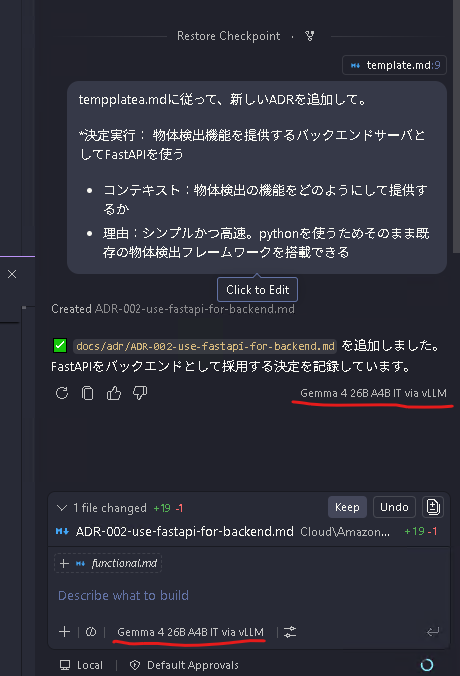
きちんと指定したモデルで推論していることがわかる。