前回はデータの読み込みのパフォーマンス測定を実施しました。今回はインデックスの作成を行い、読み込み性能の改善を行いたいと思います。
Introduction
前回は、結果も課程も散々でした。
環境は前回と同じです。
Explanation
インデックスの設定
Indexes can support the efficient execution of queries. MongoDB automatically creates an index on the _id field upon the creation of a collection.
訳: インデックスは効率的なクエリの実行をサポートすることができます。MongoDBは自動的に _id フィールド上にコレクション作成時にインデックスを作成します。
と言っています。
既にインデックスが張られているといっています。
といっても、_idフィールドなので、これまでの検索には影響しないと思います。
追加で設定する場合は、
var keys = Builders.IndexKeys.Ascending().Ascending(); await collection.Indexes.CreateOneAsync(keys);
と、するようです。
というわけで、前回の3種のオブジェクトの No プロパティ に昇順のインデックスを設定してみます。
こんな感じです。
1 | private static void SetSmallIndex(MongoClient mongoClient) |
インデックスの設定後
割と時間がかかりました。1,000,000件も登録されていればそうでしょう。
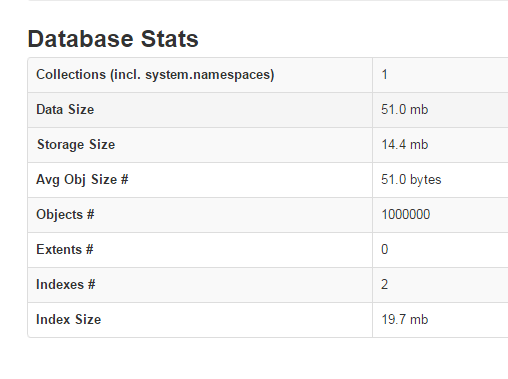
mongo-expressで確認すると、Indexes # が 2 になっています。
そして、前回と同じように、検索を実行します。検索結果の個数は10になります。
その結果が下記になります。
| オブジェクトサイズ/オブジェクト数 | 1,000,000 | 1,000,000 (インデックス適用後) |
|---|---|---|
| Small (51.0 bytes) | 420.8 ms | 610.8 ms |
| Middle (80.1 kb) | 221577.1 ms | 586 ms |
| Large (100 kb) | 計測不可 | 588 ms |
劇的に改善しました。370倍です。Largeに至っては計測できるようにさえなりました。
Smallが悪化してますが、誤差でしょう。多分。
実行後、mongod.exe のメモリ量は大きく増えていません。
検索結果の個数は影響するか?
前回、メモリ確保が原因なのか、途中で例外を投げて落ちました。
今回は、検索結果の個数が1,000,000から10になるようにしてあります。
では、これを変化させたら、検索速度はどう変化するでしょうか? 1,000,000件のデータを対象に、検索結果の個数が増えていった場合のパフォーマンスを下記に記載します。
| オブジェクトサイズ/検索結果数 | 10 | 100 | 1,000 | 10,000 | 100,000 |
|---|---|---|---|---|---|
| Small (51.0 bytes) | 610.8 ms | 515.6 ms | 558.5 ms | 582.8 ms | 956.2 ms |
| Middle (80.1 kb) | 586 ms | 512 ms | 1571.4 ms | 7171.2 ms | 計測不可 |
| Large (100 kb) | 588 ms | 494.7 ms | 1870.2 ms | 11292.6 ms | 計測不可 |
増えていくごとに悪化していく傾向です。
ただし、劇的に悪化しているのは、初回のクエリだけ100秒とかで、それ以降はキャッシュが聞いています。それでも、後半は 2,000 ms とかかかっていますが。
それでも、インデックスを設定する前と比べたら、劇的すぎる改善です。
Conclusion
バイナリファイルを扱う際は、必ずインデックスを設定し、検索のパフォーマンスを向上させるのと、検索途中の結果でOutOfMemoryExceptionを発生させないようにする必要があります。
必要なら複数のインデックスを設定して、結果が少なくなるようするべきです。
Source Code
テストに使った最終的なコードは下記になります。
https://github.com/takuya-takeuchi/Demo/tree/master/Database/MongoDB/MongoDB7