Introduction
前回 は ollama + Open WebUI によるローカル LLM 環境を構築したが、今回は ollama を vLLM に置き換えてみる。
どっちでもいいのだが、調べてみると下記のような違いがあった。
| 特徴 | Ollama | vLLM |
|---|---|---|
| 主な用途 | ローカル開発 | 高性能なプロダクション環境 |
| パフォーマンス | 個々の開発者にとって使いやすいアプローチ | 高負荷時における優れたスループットと応答性 |
| 推奨される対象 | 個人開発者 | エンタープライズ(企業)アプリケーション |
会社で使うことも考え vLLM も試してみる。
How to setup?
前回 Open WebUI はインストール済みなので、差分のみをチェック。
1. vLLM のインストール
docker で自動起動も含めて設定。
公式含めて、よくある事例では --model を指定しているが、省略も可能。
省略すると Qwen/Qwen3-0.6B を指定したものとみなされる。--gpu-memory-utilization も省略可能だが、デフォルトは 0.9 (0.0 から 1.0 を指定可能) であり、これはモデルの重み、アクティベーション、および KV キャッシュのアクセラレーターメモリー使用率を示すので、値が大きいとメモリ不足で起動しないこともある。
1 | $ sudo docker run --gpus all -d -it -p 11435:8000 \ |
ホスト側の公開ポートはお好みで。
しばらくしたら起動が完了するので疎通確認を行う。
1 | $ curl http://localhost:11435/v1/models | jq |
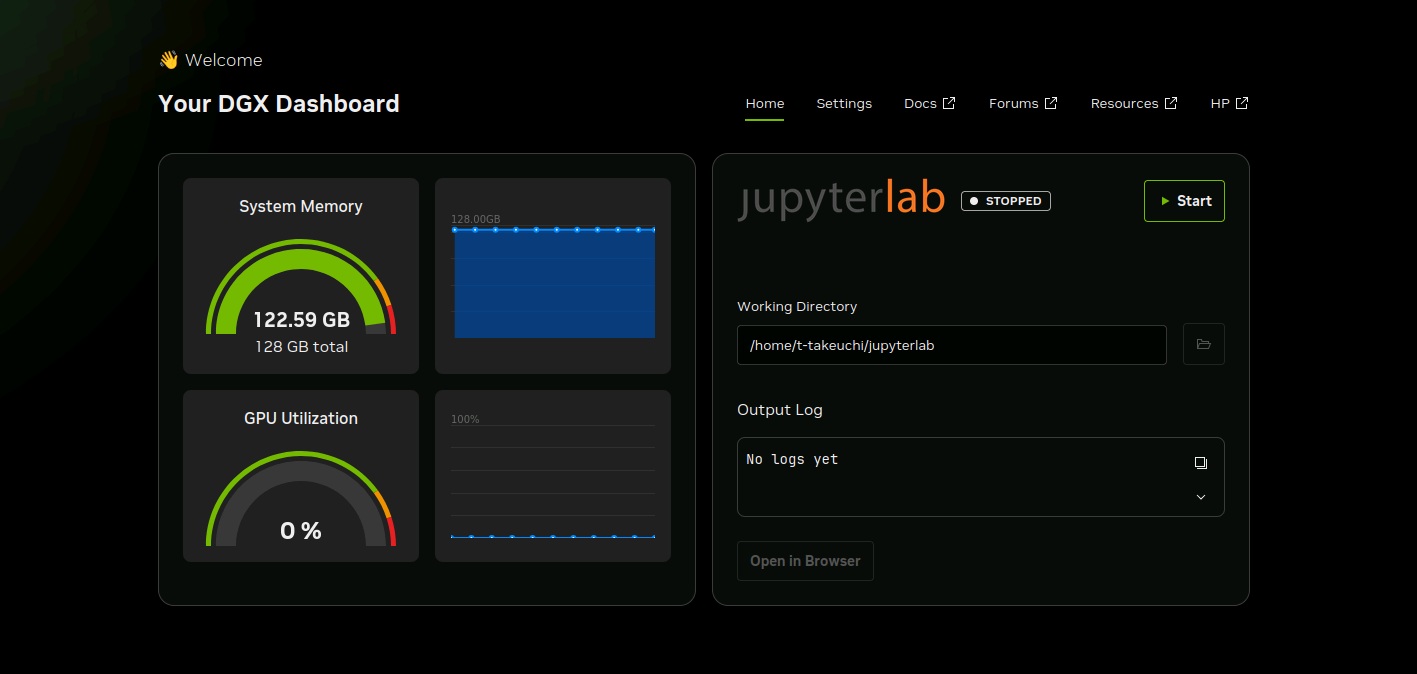
--gpu-memory-utilization 0.9 の場合のメモリ使用量。
起動前に 6-7 GB を占有していたので、 128 * 0.9 = 115 を加算しておおよそ一致する。
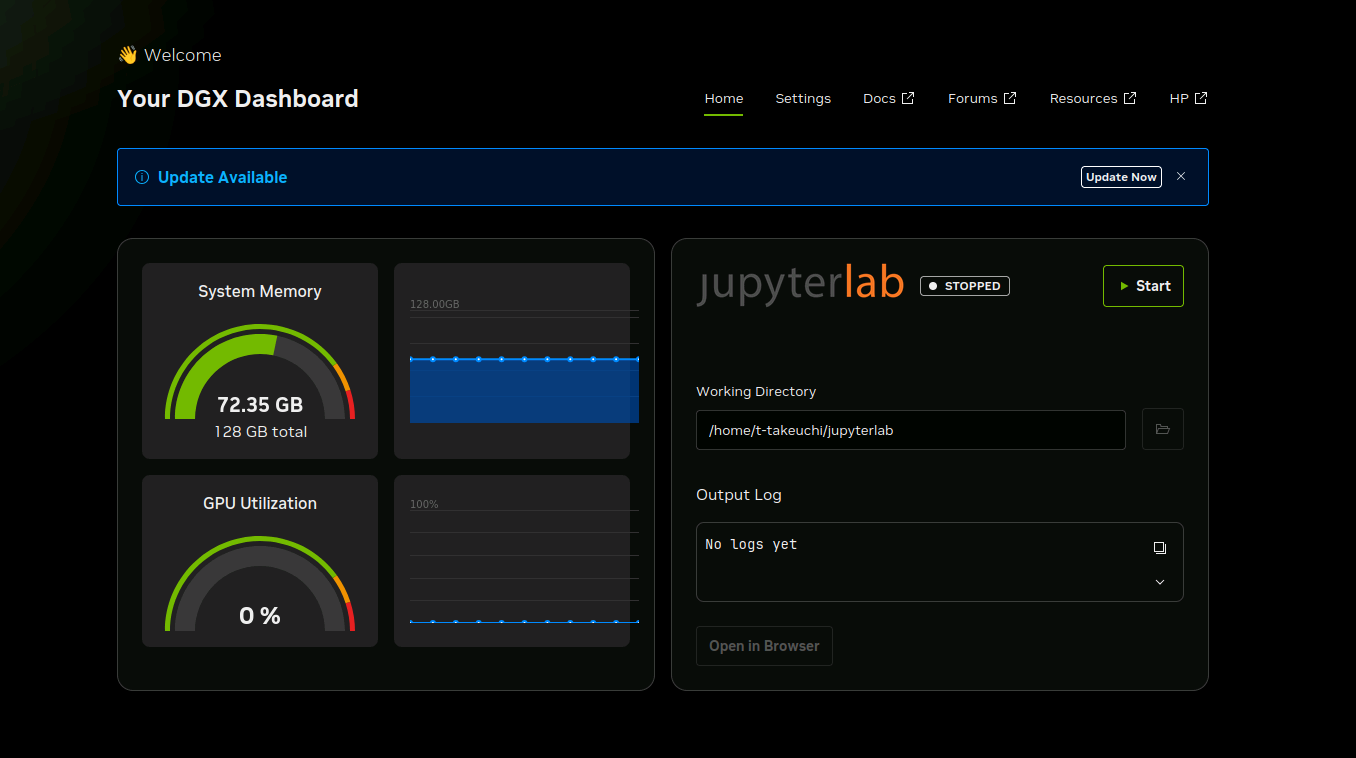
--gpu-memory-utilization 0.5 の場合のメモリ使用量。
2. Open WebUI の設定
右上 のアイコンから 管理者パネル を選択
設定 を選択
接続 を選択
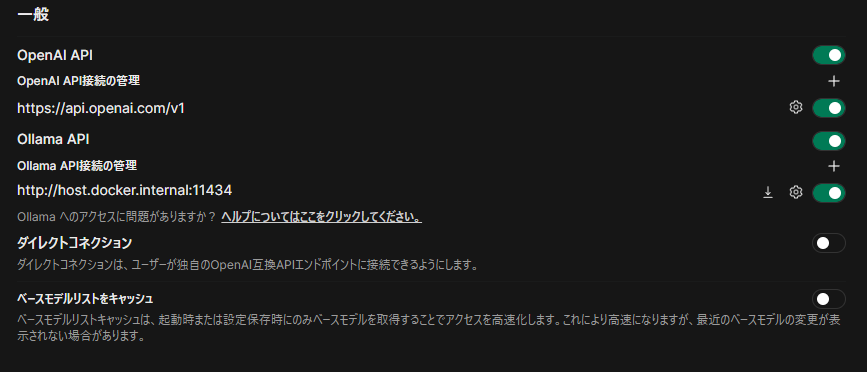
Open API を ON に変更し、 OpenAI API接続の管理 の右側にある設定ボタンを押下。
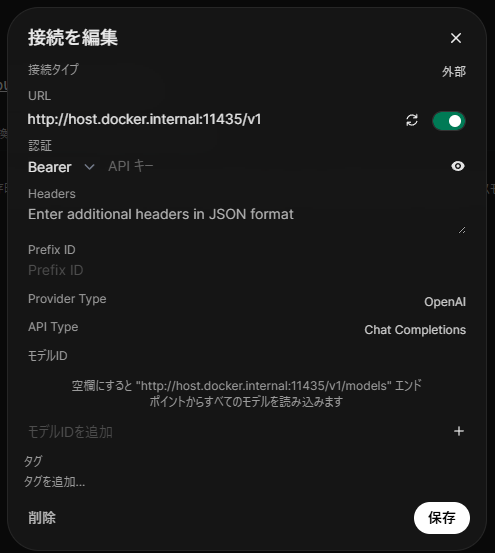
URLを http://host.docker.internal:11435/v1 に変更し、右側の 接続を確認 アイコンをクリックし、疎通を確認。
問題なければ、画面右上に サーバー接続が確認されました というトーストが表示される。
保存 ボタンを押下。
完了したいつものチャット画面に戻り、左上に先ほど指定したモデルが表示されているのを確認する。
試しに日本語で挨拶し、正しく動作していることを確認。
(一番最初の会話はモデルの初期化や初回推論の影響で遅いため注意)
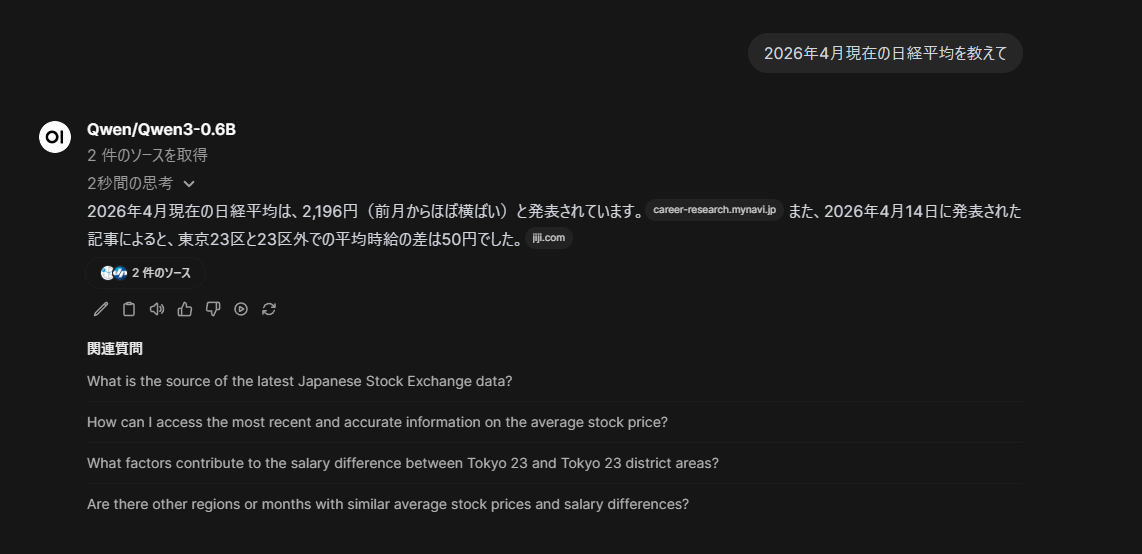
Web 検索も設定済みなので、そちらも正しく動作していることがわかる。
が、日経平均値がおかしい。
よくみると、ソースの参照が「アルバイト・パート平均時給レポート」になっている…
とりあえず、Web 検索が動いたのでよし。
3. モデルの変更
ollama とは異なり、モデルを追加したり切り替えるにはコンテナを起動しなおし、 --model 引数を変更する必要がある。
Hugging Face からモデルをダウンロードする必要があるため、Hugging Face にサインアップし、アクセストークンを取得する。
ログイン後、右上のメニューから Access Tokens を押下。
Create new token を押下。
Token type を Read に設定し、Token name に適当な名前を入力し、Create token を押下。
アクセストークンをコピー。
コピーしたアクセストークン及び利用したいモデルの名前をメモ。
例えば、google/gemma-4-26B-A4B-it を利用するなら、 $HF_TOKEN に先ほどコピーした値を設定し、下記のようにする。
1 | sudo docker run --gpus all -d -it -p 11435:8000 \ |
docker logs で起動ログを見ればわかるが、モデルのダウンロードに時間がかかるので適宜確認。
1 | (EngineCore pid=96) <frozen importlib._bootstrap_external>:1301: FutureWarning: The cuda.nvrtc module is deprecated and will be removed in a future release, please switch to use the cuda.bindings.nvrtc module instead. |
動作確認も問題なし。
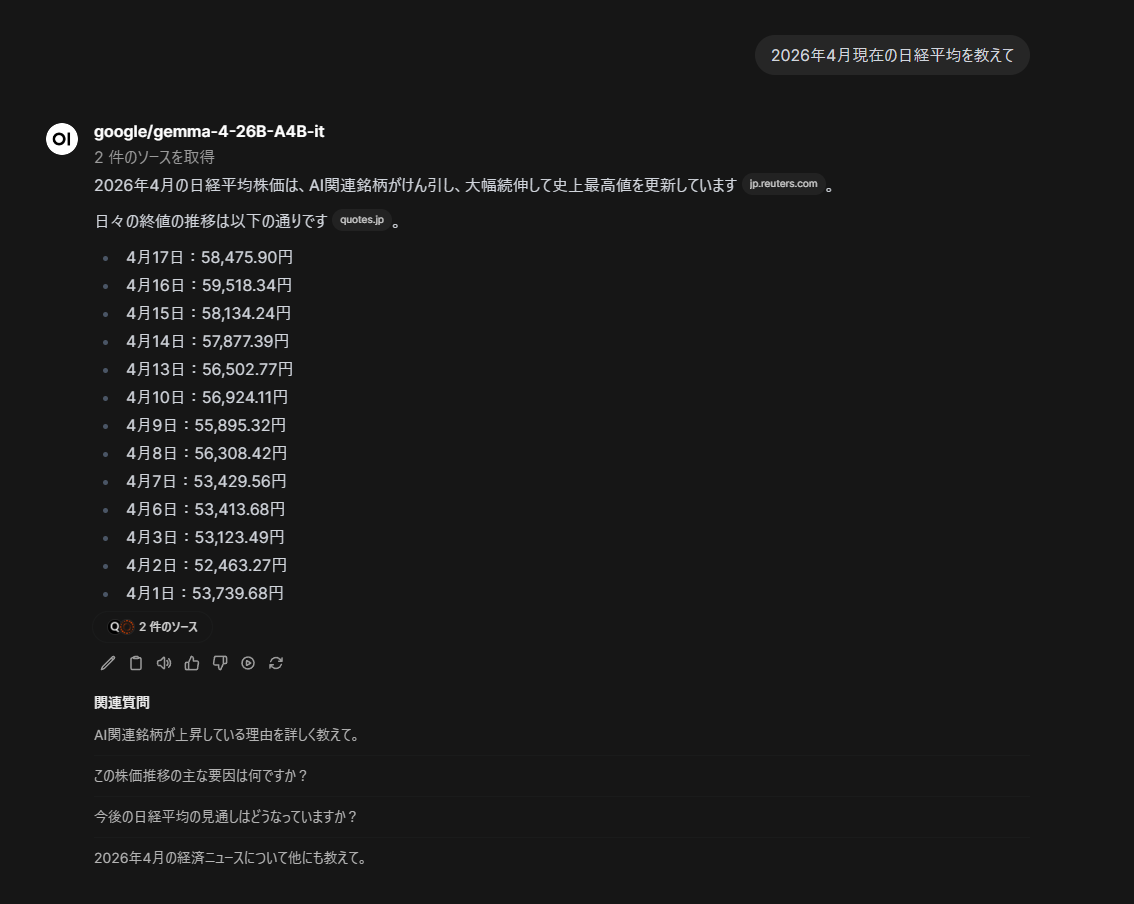
Qwen/Qwen3-0.6B のような軽量モデルに比べて良好な結果を返してくれている。
ところで、 vLLM は先に書いたようにエンタープライズ向けであり、モデルを頻繁に変更するような運用は想定しないと思われる。--gpu-memory-utilization など事前に占有するメモリを決めておくような設計からも、この想定が正しいように感じる。